NeuroGym是一个经过仔细挑选的神经科学任务集合,具有公共接口。其目标是促进在神经科学任务上神经网络模型的训练。
NeuroGym是一个工具包,可以让您在许多已建立的神经科学任务技术上训练任何神经网络模型,如标准的监督学习或强化学习。
该教程用于理解Neurogym的任务结构,程序运行环境为Google Colab。本文翻译自Neurogym官方文档,对应的代码 [Open in Colab]
neurogym是基于gym开发的,很多参数的设置用起来不是很顺手,不清楚源代码怎么写的,有些代码不太好理解。但本质上就是继承了gym的一些方法,生成行为任务的数据。后面可能不会直接用neurogym,而是仿写并实现课题组内已有的范式。
安装
1
2
3
4
| ! pip install gym
! git clone https://github.com/gyyang/neurogym.git
%cd neurogym
! pip install -e .
|
OpenAI gym 任务
Neurogym任务遵循基本的OpenAI gym任务形式。每个任务定义为一个Python类,继承自gym.Env类。
在这一节中,我们描述一个OpenAI gym任务的基本结构。
在__init__方法中,必须定义两个属性,self.observation_space和self.action_space,它们描述了观测(网络输入)和动作(网络输出)的空间类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import warnings
warnings.filterwarnings("ignore")
import numpy as np
import gym
class MyEnv(gym.Env):
def __init__(self):
super().__init__()
self.observation_space = gym.spaces.Box(low=0., high=1., shape=(2,))
self.action_space = gym.spaces.Discrete(3)
def step(self, action):
ob = self.observation_space.sample()
reward = 1.
done = False
info = {}
return ob, reward, done, info
def reset(self):
ob = self.observation_space.sample()
return ob
env = MyEnv()
print('sample random observation value')
print(env.observation_space.sample())
print('sample random action value')
print(env.action_space.sample())
|
另一个需要定义的关键方法是step方法,用于接收智能体的动作后更新环境、输出观测和奖励。
step方法将action作为输入,并输出智能体的下一个观测observation,智能体获得的标量奖励reward,用于描述环境是否需要重置的布尔值done,以及包含任何额外信息的字典info。
如果环境通过内部状态描述,reset方法需要重置这些内部状态。该方法返回一个初始观测observation。
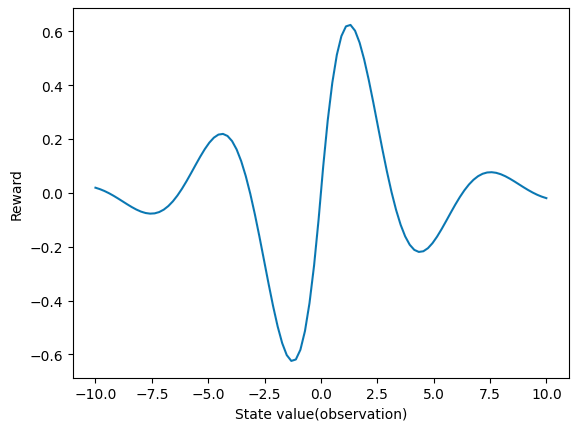
下面我们定义一个简单的任务,智能体沿着一维直线采取动作。奖励由智能体在直线上的位置决定。
1
2
3
4
5
6
7
8
9
| import matplotlib.pyplot as plt
def get_reward(x):
return np.sin(x) * np.exp(-np.abs(x)/3)
xs = np.linspace(-10, 10, 100)
plt.plot(xs, get_reward(xs))
plt.xlabel('State value(observation)')
plt.ylabel('Reward')
|

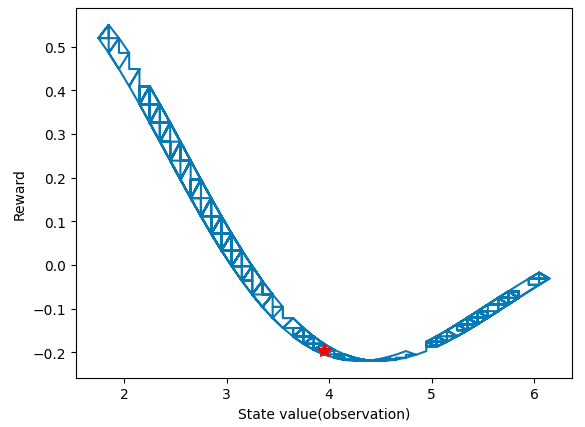
智能体可以与环节迭代地互动,红色星星表示智能体的初始状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| class MyEnv(gym.Env):
def __init__(self):
super().__init__()
self.observation_space = gym.spaces.Box(-10,10,(1,))
self.action_space = gym.spaces.Discrete(3)
self.state = 0.
def step(self,action):
self.state += (action - 1.) * 0.1
self.state = np.clip(self.state, -10, 10)
ob = self.state
reward = get_reward(self.state)
done = False
info = {}
return ob, reward, done, info
def reset(self):
self.state = self.observation_space.sample()
return self.state
env = MyEnv()
ob = env.reset()
ob_log = list()
reward_log = list()
for i in range(1000):
action = env.action_space.sample()
ob, reward, done, info = env.step(action)
ob_log.append(ob)
reward_log.append(reward)
plt.plot(ob_log, reward_log)
plt.xlabel('State value(observation)')
plt.ylabel('Reward')
|
基于试次(trial)的Neurogym任务
许多神经科学和认知科学的任务有试次结构。neurogym.TrialEnv为常见的基于试次任务提供了类。它与gym.Env的主要不同在于_new_trial()方法,该方法可以生成新试次的摘要信息,并且可选择地,生成观测和真实值输出。除此之外,用户提供了_step()方法而不是step()方法。
_new_trial()方法接收任意键-值参数**kwargs,输出一个包含该试次相关信息的字典trial。这个字典在_step中可以作为self.trial访问。
这里我们定义一个简单的任务,智能体在每个试次需要基于它的观测做出一个二元决策。每个试次只有一个时间步。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| import neurogym as ngym
from neurogym import TrialEnv
class MyTrialEnv(TrialEnv):
def __init__(self):
super().__init__()
self.observation_space = gym.spaces.Box(-1., 1., (1,))
self.action_space = gym.spaces.Discrete(2)
self.next_ob = np.random.uniform(-1, 1, size=(1,))
def _new_trial(self):
ob = self.next_ob
self.next_ob = np.random.uniform(-1, 1, size=(1,))
trial = dict()
trial['ground_truth'] = (ob > 0) * 1.0
return trial
def _step(self, action):
ob = self.next_ob
reward = (action == self.trial['ground_truth']) * 1.0
done = False
info = {'new_trial': True}
return ob, reward, done, info
env = MyTrialEnv()
ob = env.reset()
print('Trial', 0)
print('Observation', ob)
for i in range(5):
action = env.action_space.sample()
print('Action', action)
ob, reward, done, info = env.step(action)
print('Reward', reward)
print('Trial', i+1)
print('Observation', ob)
Trial 0
|
TrialEnv类定义了两个抽象方法:_new_trial()和_step()。这两个方法没有具体的实现,只有方法的声明和文档字符串。这样做的目的是强制任何继承TrialEnv的子类必须实现这两个方法,以便成为一个完整的环境。
环境reset时会调用new_trial()方法,step之后也会调用new_trial()方法,只不过这些是在父类中实现的,我们创建环境时只需要把_new_trial()方法实现即可。
具体可见neurogym目录下的core.py文件。
在基于试次的任务中包含时间,阶段和观测
许多神经科学和认知科学任务遵循额外的时间结构,这些结构被包含进neurogym.TrialEnv。这些任务通常
- 描述为实际时间而不是离散时间步。例如,任务可以持续3s
- 每个试次包含许多时间阶段,比如刺激阶段和响应阶段。
为了包含这些特征,neurogym任务通常支持设置每一步的时间长度dt(单位为ms),以及每个时间阶段的时间长度timing。
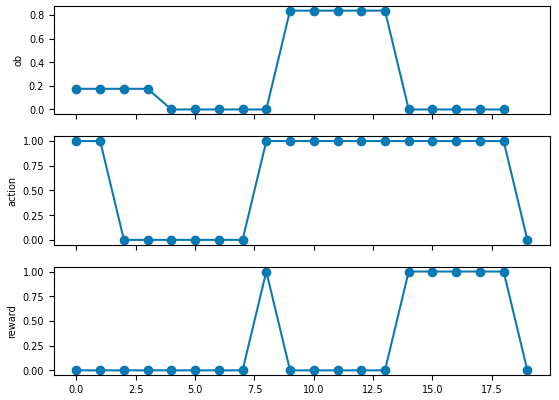
例如,考虑下面的二元决策任务,有500ms的刺激阶段,跟着500ms的决策阶段。可以通过self._new_trial()中的self.add_period()在每个试次中添加阶段。在_step()中,你可以通过self.in_period(period_name)检查任务当前所处的阶段。
关于这段代码,我真的向多说几句:官方文档给的这段示例代码有点问题,按它原本的写法,stimulus阶段不应该获得奖励,但是奖励却为1。我调试了很久,总觉得observation、action和reward之间错位了,但看代码又找不出具体问题。今天上午终于发现了,在env.reset()时stimulus阶段就开始了,等进入循环时时间步已经走了一步了,但是此时仍用初始的观测执行env.step(action),就会造成reward不匹配。所以采取的修改方式是删掉循环外存储的ob,直接从第二个时间步开始,这样就不会错位了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| import numpy as np
import neurogym as ngym
import gym
from neurogym import TrialEnv
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'DejaVu Sans'
class MyDecisionEnv(TrialEnv):
def __init__(self, dt=100, timing=None):
super().__init__(dt=dt)
self.timing = {'stimulus':500, 'decision':500}
if timing:
self.timing.update(timing)
self.observation_space = gym.spaces.Box(-1., 1., (1,))
self.action_space = gym.spaces.Discrete(2)
def _new_trial(self):
periods = ['stimulus', 'decision']
self.add_period(periods)
stimulus = np.random.uniform(-1, 1, (1,))
trial = dict()
trial['stimulus'] = stimulus
trial['ground_truth'] = (stimulus > 0) * 1.0
trial['new_trial'] = True
return trial
def _step(self, action):
if self.in_period('stimulus'):
ob = np.array([self.trial['stimulus']])
reward = 0.
else:
ob = np.array([0.])
reward = (action==self.trial['ground_truth'])*1.0
done = False
info = {'new_trial': False}
return ob, reward, done, info
log = {'ob':[], 'action':[], 'reward':[]}
env = MyDecisionEnv(dt=100)
ob = env.reset()
for i in range(20):
action = env.action_space.sample()
log['action'].append(action)
ob, reward, done, info = env.step(action)
log['reward'].append(reward)
log['ob'].append(ob)
log['ob'] = log['ob'][:-1]
f, axes = plt.subplots(3, 1, sharex=True)
for ax, key in zip(axes, ['ob', 'action', 'reward']):
ax.plot(log[key], 'o-')
ax.set_ylabel(key)
|
在每个试次的开始设置观测和真实值
在许多任务中,每个试次的观测和真实值是提前确定的,可以在self._new_trial()中设置。生成的观测和真实值可以用作监督学习的输入和目标。
观测和真实值可以在self._new_trial()中通过self.add_ob()和self.set_groundtruth()方法设置。用户可以用它们的名字指明观测的阶段和位置。比如,self.add_ob(1, period='stimulus', where='fixation')。
允许用户通过self.ob和self.gt访问整个试次的观测和真实值,并通过self.ob_now和self.gt_now访问它们的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| import numpy as np
import neurogym as ngym
import gym
from neurogym import TrialEnv
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'DejaVu Sans'
class MyDecisionEnv(TrialEnv):
def __init__(self, dt=100, timing=None):
super().__init__(dt=dt)
self.timing = {'stimulus':500, 'decision':500}
if timing:
self.timing.update(timing)
name = {'fixation': 0, 'stimulus': 1}
self.observation_space = ngym.spaces.Box(low=-1, high=1, shape=(2,), name=name)
name = {'fixation':0, 'choice':[1,2]}
self.action_space = ngym.spaces.Discrete(3, name=name)
def _new_trial(self):
periods = ['stimulus', 'decision']
self.add_period(periods)
stimulus = np.random.uniform(-1, 1, (1,))
self.add_ob(1, period="stimulus", where="fixation")
self.add_ob(stimulus, period="stimulus", where="stimulus")
ground_truth = int(stimulus > 0)
self.set_groundtruth(ground_truth, period="decision", where="choice")
trial = dict()
trial['stimulus'] = stimulus
trial['ground_truth'] = ground_truth
return trial
def _step(self, action):
reward = (action==self.gt_now) * 1.0
done = False
info = {'new_trial': False}
return self.ob_now, reward, done, info
env = MyDecisionEnv()
_ = env.reset()
trial = env.new_trial()
ob, gt = env.ob, env.gt
print(trial)
print(ob)
print(gt)
fig = ngym.utils.plot_env(env, num_trials=2)
|
补充知识
- self: 在Python中,当定义一个类方法时,第一个参数通常被称为
self,它代表类的实例对象,允许在类的方法中访问对象的属性和其他方法。
- super().init(): 在面向对象编程中,当创建一个子类时,通常需要继承父类的属性和方法,可以使用
super().__init__()来调用父类的构造方法,确保父类的初始化代码得以执行。当super().__init__()不带参数时,它会调用父类的构造方法,并将子类的实例作为第一个参数传递给父类的构造方法。
- 继承: 在面向对象编程中,继承是一种重要的概念,它允许你创建一个新的类(子类),从一个现有的类(父类)继承属性和方法。子类可以访问父类的属性和方法,并且还可以添加自己的属性和方法。如
class Child(Parent): 这样的语法表示子类 Child 继承了父类 Parent。
- 时间步(time step): 在计算机科学和数学中,时间步长通常用于描述在离散时间模型中的时间间隔。理解时间步长的关键是认识到许多模型和系统在仿真或模拟时需要将时间划分成离散的部分,而时间步长就是这个离散化的单位。在每个时间步长内,系统的状态会被更新,从而使得系统在连续时间范围内的变化可以通过离散时间步长来近似。
- 抽象方法: 抽象方法是指在父类中声明但没有具体实现的方法,它只有方法名、参数列表和文档字符串,没有具体的代码实现。子类继承这个父类时,必须实现这些抽象方法,否则子类也会被视为抽象类,无法实例化。
参考内容